
Donnerstag, 29. Mai 2026, 15:03 Uhr. In einem zwölfköpfigen iOS-Team landet in Slack #ios-ci ein Run-Link mit dem Satz: „Lokal in Xcode zwölf Minuten durch — der PR hängt noch in Queued.“ Eine halbe Stunde lang kommt nichts — solche Meldungen kennt man. Nach 48 Minuten folgt die Ergänzung: „Queued 47m, Run 12m. Heute Abend kein Merge mehr.“ Ein Kollege aus dem Release-Track schaut vom Meeting aufs Handy: „Der ios-release-Archive-Job steht noch in der Queue — die PR-Linie ist wieder blockiert.“
Die Screenshots stammen aus Kundenmaterial, das uns bei der Fehlersuche zur Verfügung stand — geschwärzt, Zahlen unverändert. Die Statistik lässt sich anhand der GitHub-Dokumentation zu Job-Ausführungszeit und queue_wait_seconds selbst nachvollziehen.
Zwei Apps in einem Monorepo, CI vollständig auf GitHub-gehosteten macOS-Runnern. 2025 ging das noch — im Frühjahr 2026 wurde der Feedback-Loop so lang, dass man die Geduld verliert. GitHub Actions ist nicht „kaputt“, aber für iOS-Teams fühlt es sich zunehmend wie ein überfüllter Pendelbus in der Rushhour an.
Dieser Donnerstag: Job-Seite öffnen — gelber Balken viermal so lang wie grün
Sie schickten uns einen Screenshot der Job-Seite von Run #18472910356 — kein Hörensagen, sondern eine Timeline mit harten Zahlen. Gelb (Queued): 47 Min. 12 Sek., Grün (Run): 12 Min. 4 Sek., unten im UI: queue_wait_seconds: 2832, run duration: 724. Die Formel ist brutal einfach: wait time >> run time.
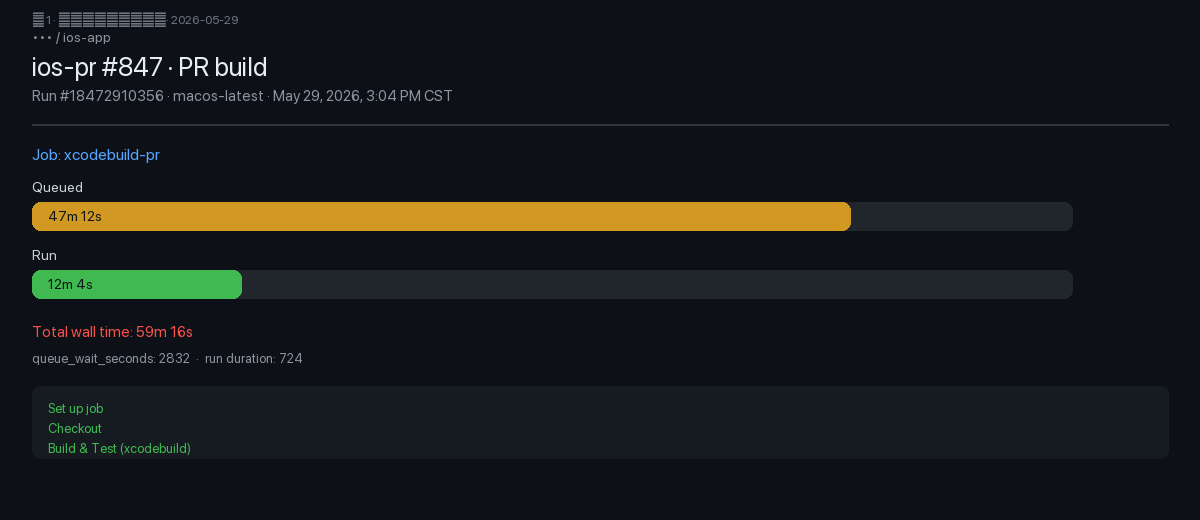
ios-pr.yml · macos-latest · 2026-05-29 15:04 CSTIm Meeting diskutierte das Team noch, ob man -jobs parallelisieren oder den DerivedData-Cache-Key anpassen soll — aber niemand hatte die letzten zehn macOS-Jobs nach queued- und run-Spalten ausgewertet. Auf der Release-Seite war die Lage noch frustrierender: ios-release.yml packte xcodebuild archive, Notarisierung, TestFlight-Upload und PR-Unit-Tests in dieselbe Pipeline auf demselben macos-latest-Label. Ein Archive dauert 25–40 Minuten, blockiert knappe Concurrency-Slots und zieht schnelle PR-Feedback-Jobs mit in die Warteschlange.
Wenn du jetzt nur die Queued-Zeit angehen willst, starte mit unserem macOS-Runner-Queue-Diagnose-Runbook. Der Wendepunkt kam, als das Team akzeptierte, dass das Problem bei der Kapazität liegt — und das Meeting mit Zahlen statt Bauchgefühl überzeugte.
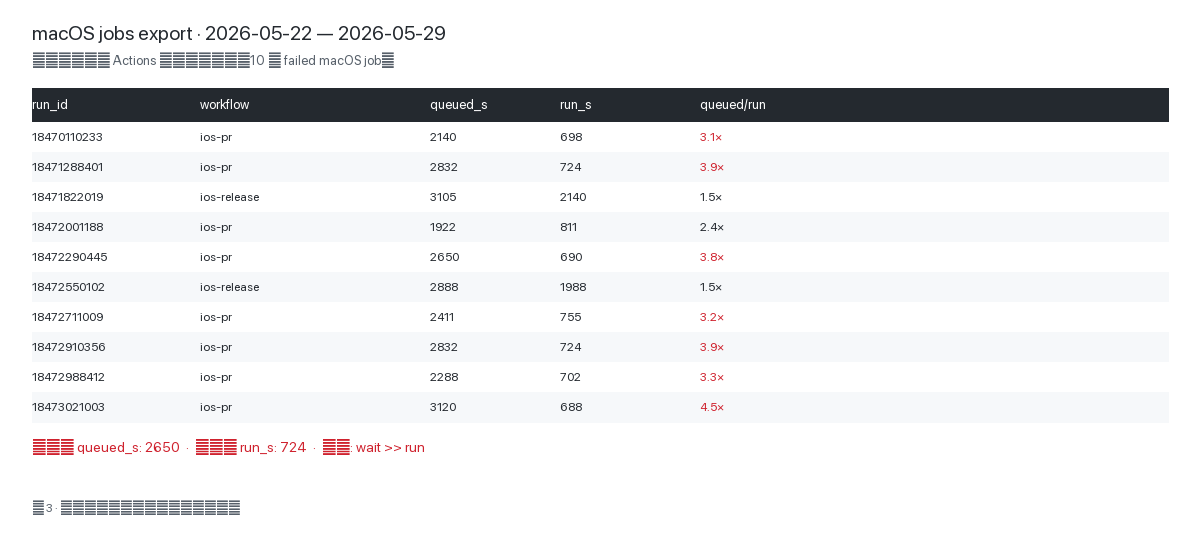
Belege: Handkopierte Tabelle aus zehn failed Jobs
Vor dem Stand-up am 30. Mai kopierte jemand zehn failed macOS-Jobs aus der Actions-Liste ab (siehe Abb. 3). Kein BI-Dashboard — nur eine Tabelle mit zwei Kernspalten: queued_s und run_s. Median queued 2650 Sek., run 724 Sek.; das Verhältnis stieg bis 4,5×. Ein paar Sekunden Stille im Meeting: Niemand sprach mehr davon, dass Xcode 17.4 schuld sei.
| Oft fälschlich gedacht | Signal in Abb. 3 | Wahrscheinlichere Ursache |
|---|---|---|
| GitHub-Ausfall | 10/10 queued_s > run_s | macOS-Concurrency-Cap, Schwergewichts-Jobs blockieren Slots |
| Projekt wächst | run_s stabil bei 690–811s | Compile ist nicht der Engpass — Warten schon |
| Chaotische Pushes | Mehrere Runs pro PR (siehe Abb. 2) | Agent-/Bot-Schleife |
| Abgelaufenes Zertifikat | Signaturfehler über verschiedene Runs verteilt | Keychain-Cold-Start, parallele Konkurrenz |
Abb. 2: Derselbe PR wurde sechsmal getriggert
Queue war nur die erste Hälfte. Im März hatte das Team einen Coding-Agent angebunden: CI rot → Logs lesen → automatischer Commit → Actions erneut. Die Checks-Seite von PR #847 zeigt es deutlich — sechs Workflow-Runs, davon vier mit Bot-Actor, zwei menschlich. Formal noch CI; faktisch eine Retry-Schleife. Mehr dazu in Was passiert, wenn CI zur Endlosschleife wird.
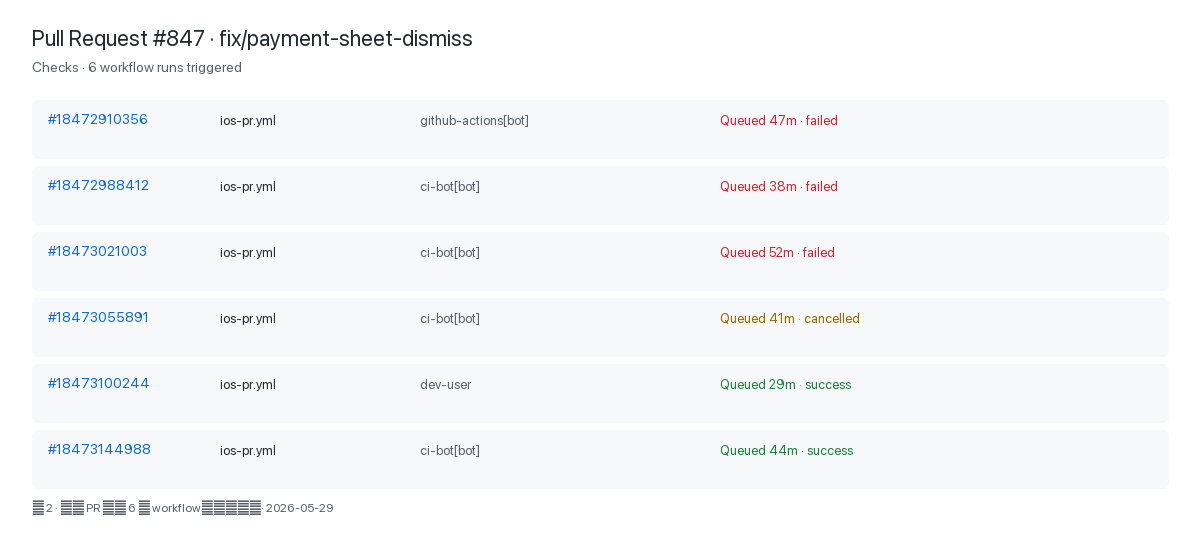
ios-pr.yml (4× Bot · 2× Mensch) · 2026-05-29Später sagte jemand im Team scherzhaft: „CI ist nicht tot — wir haben es zum Perpetuum mobile gemacht.“ Das Problem ist nicht die Automatisierung, sondern dass jeder Bot-Fix die gemeinsame Queue belastet — ohne dedizierten Runner-Pool.
Wendepunkt: ein Cloud Mac und der Pipeline-Split am 31. Mai
Nach der Handtabelle zerlegten sie die Logs nach Job-Typ: etwa 70 % PR-Checks und Integrations-Builds, 20 % Simulator-Unit-Tests, 10 % Archive und Upload — fast identisch mit der Zusammensetzung eines anderen Teams mit 500 iOS-CI-Runs pro Tag. Vorschläge reichten von acht Mac minis bis Xcode Cloud. Am Ende setzten sie zwei Dinge um:
Am 31. Mai: Apple-Silicon-Cloud-Mac mieten, als Self-hosted Runner registrieren (Labels self-hosted, macOS, cloud-mac). Das Gegenexperiment war schlicht: derselbe Commit, je 50 Builds auf gehostetem macos-latest und auf dem Cloud Mac — die Queued-Varianz schrumpfte von „mal 40 Minuten, mal 5“ auf „meist einstellige Sekunden“.
Pipeline-Split in derselben Nacht. Archive, Export und Upload aus ios-pr.yml nach ios-release.yml; die PR-Linie nur noch build plus Unit-Tests. Dazu ein Warm-up-Cron: täglich nachts xcodebuild build auf dem Cloud Mac, DerivedData bleibt auf der Platte — stabiler als jedes Mal aus actions/cache kalt zu starten.
Abb. 6 · Median Wall Time derselben Mannschaft (PR-Build, je 50 Läufe über zwei Wochen)
Datenquelle: Kunden-Gegenexperiment-Logs (2026-05-31 — 06-08), querverifizierbar mit Abb. 1 und Abb. 4.
9. Juni: Abb. 4 — endlich eine Job-Seite, die Sinn ergibt
Zwei Wochen nach dem Split, Montagmorgen: In Slack landet ein Screenshot von Run #18510488201 — queued 41 Sek., run 9 Min. 17 Sek., Runner self-hosted, cloud-mac. Kein Applaus, nur ein Emoji — in iOS-Teams ist das das höchste Lob.
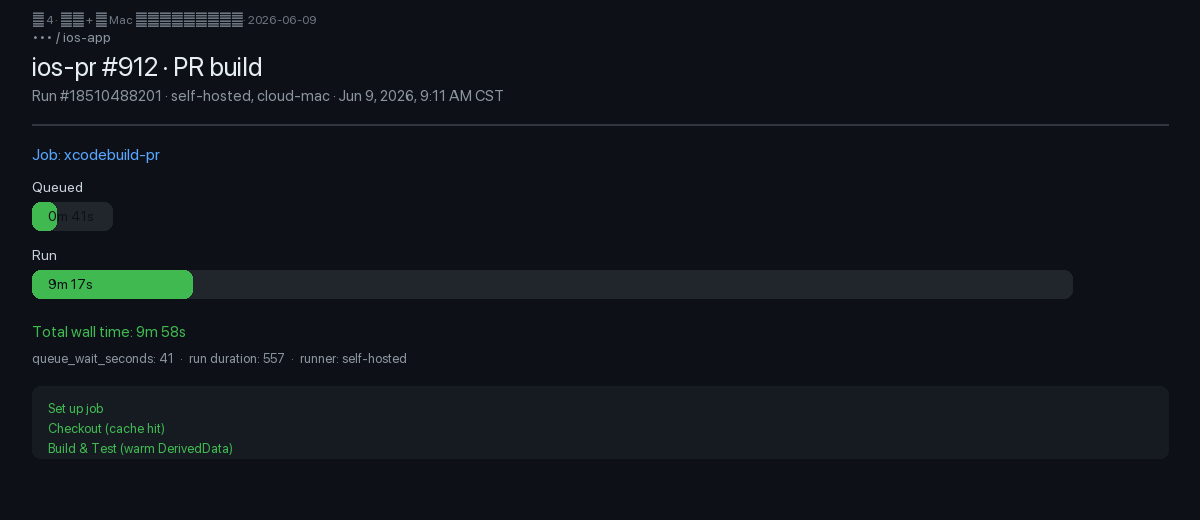
self-hosted, cloud-mac · 2026-06-09 09:11 CSTLeitplanken für den Agent: vier Regeln im Wiki
Der Pipeline-Split löste das Archive-Problem auf der PR-Linie; die Bot-Schleife brauchte eigene Maßnahmen. Der Bot bekam einen separaten Branch und einen Runner-Pool mit niedrigerer Priorität — Merge erst nach menschlichem Review. Vier harte Regeln im Wiki:
- PR-Workflow: kein Archive / kein Store-Upload
- macOS-Jobs mit
concurrency, damit derselbe Branch nicht stapelt - Self-hosted Runner mit Labels — kein Mischen mit Experiment-Workflows
- Agent-Auto-Push nur auf separatem Branch, kein Direkt-Push auf geschützte Branches
queue_wait_seconds und run duration (wie Abb. 3); zähle Workflow-Runs pro PR (wie Abb. 2); prüfe, ob Archive noch im PR-Workflow steckt. Ist der Median queued > run, zuerst Runner-Kapazität — nicht Compile-Flags.
Die neue Lösung: GitHub behalten, Kapazität wechseln
Die Erfahrung dieses Teams lässt sich auf vier Punkte reduzieren, die iOS-Teams 2026 am häufigsten umsetzen: Cloud-Mac-Self-hosted-Runner-Pool, PR/Release-Split, Warm-up und Disk-Cache, Agent-Leitplanken. Ersetzt Xcode Cloud das? Gut für reine Apple-Ökosystem-Workflows; mit GitHub-PR-Checks und gemischten Android-Linien behalten die meisten Actions und verlagern nur Archive auf dedizierte macOS-Kapazität.
| Wenn euer Team eher so aussieht … | Typische Empfehlung |
|---|---|
| 1–3 Personen, wöchentliche Releases | Gehostetes macOS + starker Cache; Release-Archive manuell |
| 5–15 Personen, tägliche Merges | 1–2 Cloud-Mac-Self-hosted + PR/Release-Split |
| 15+ Personen, mehrere Apps | Runner-Pool nach App labeln + Warm-up-Cron |
| Agent-lastige Auto-Fixes | Eigener Bot-Pool + kein Archive im PR-Workflow |
Apples xcodebuild-Dokumentation betont Konsistenz von Scheme und Destination; bei jedem Cold Start in CI verliert „lokal grün“ an Bedeutung. Ein Kunde formulierte es so: Lieber Zertifikatsrotation und Xcode-Major-Upgrades als jeden Tag 47 Minuten gelben Balken anstarren.
Vom ersten Cloud-Mac-Self-hosted-Runner an
Wenn eure Job-Seite wie Abb. 1 aussieht — gelb länger als grün — ist die nächste sinnvolle Investition meist ein dedizierter Apple-Silicon-Cloud-Mac: als GitHub-Self-hosted-Runner registriert, wird PR-Build von „Queue-Lotterie“ zu den vorhersagbaren neun Minuten aus Abb. 4.
Zwei Wochen Gegenexperiment: derselbe Branch, je 50 Builds auf gehostetem macOS und Cloud-Mac-Self-hosted — eine Tabelle wie Abb. 3. Die Zahlen zeigen, ob Xcode langsam ist oder die Kapazität iOS ausbremst.
Mit einem vorhersagbaren Cloud Mac starten und Archive zurück auf die Release-Linie legen. VPSSpark Cloud-Mac-Tarife ansehen und den ersten iOS-Self-hosted-Runner registrieren.